- Lösungen & Produkte
- Lösungen
- Reichweite erhöhen
Mehr Sichtbarkeit für Ihre Inhalte durch zielgenaue Verbreitung
- Reichweite messen
Überprüfen Sie die Wirkung Ihrer PR-Arbeit.
- KI-Tools der APA
KI-Tools für Bild, Text und Sprache
- Reichweite erhöhen
- Produkte
- APA-NewsDesk
Medien - & Datenhub
- PR-Desk
Verbreiten, Beobachten und Recherchieren in einem Tool
- OTS
Der direkte Weg zu Medien, Pressestellen und ins Web
- APA-NewsDesk
- Produkte
- Medienbeobachtung
Alle relevanten Medienartikel frühmorgens und online verfügbar
- Content on Demand
Texte, Bilder, Grafiken in optimaler Komposition
- APA-Images
Österreichs größtes Bildangebot für News, Kreatives, Society u.v.m.
- Medienbeobachtung
- Produkte
- Housing und Hosting
Hochverfügbare und ausfallsichere IT-Infrastruktur mit 24/7-Support
- APA-Pressezentrum
High-Tech-Location mit Top-Betreuung für Ihre Events
- CompanyGPT by APA
DSGVO-konforme KI-Lösung
- Housing und Hosting
- Lösungen
- Wissen & Netzwerk
- Blogbeiträge
- Rechtliche Fragen beim Einsatz von KI
Hier erfahren Sie, wie Sie mit rechtlichen Fragen im Bereich KI umgehen müssen.
- Urheberrecht bei Fotos: Kennen Sie Ihre Bildrechte?
Kein Foto ohne Urheber- und Bildrechte - unsere Guidelines
- Rechtliche Fragen beim Einsatz von KI
- Wissen
- Blog
Interne & externe Branchennews mit dem APA-Blog
- APA-Faktencheck
APA-Faktenchecks im Kampf gegen Falschinformationen
- Blog
- Weiterbildung
- APA-Campus
Workshops und Lehrgänge für PR und Journalismus
- KI-Kompakt
KI-Kompetenz erweitern mit APA-Campus
- Whitepaper & Co.
Profitieren Sie vom Insider-Wissen unserer ExpertInnen
- APA-Campus
- Newsletter
- APA-Value-Newsletter
Aktuelles aus der APA-Gruppe
- APA-Comm-Newsletter
Aktuelles aus der Welt von APA-Comm
- APA-Value-Newsletter
- Blogbeiträge
- About APA
- About APA
- About APA-Gruppe
Auftrag, Mission, Eigentümer, Geschichte
- Facts & Figures
Die wichtigsten Zahlen und Daten auf einen Blick
- Auszeichnungen, Zertifikate und Qualitätsinitiativen
Qualität zählt
- About APA-Gruppe
- Nachrichtenagentur
- Die Redaktion
True and unbiased News
- Internationales Netzwerk
Nachrichtenagenturen im Verband
- Alfred-Geiringer-Stipendium
Förderung des Qualitätsjournalismus
- Die Redaktion
- Innovation & Sharing
- Medienübergreifende Lösungen
Die APA als Digital Cooperative
- APA-medialab: Innovationszentrum
Research, Prototyping und Design Sprints
- Medienübergreifende Lösungen
- Presse
- Presseinformationen
Neuigkeiten aus der APA-Gruppe
- Pressefotos und Logos
Management, APA-Zentrale und Logopakete
- Pressekontakt
Kontaktieren Sie uns
- APA-Value-Newsletter
Aktuelles aus der APA-Gruppe
- Presseinformationen
- About APA
- Karriere
- Kontakt
Wenn Algorithmen schreiben lernen
Automatisierte Texterstellung ist im E-Commerce-Bereich längst an der Tagesordnung. Bei hunderten neuer Produkte, die täglich in großen Online-Shops dazukommen, liegt es nahe, bei der Produktion von Produktbeschreibungen auf "Kollege Computer" zu setzen. Doch auch Medienunternehmen entdecken das Potenzial der Technologie im Rahmen von Pilotprojekten immer mehr für sich.
Ein Thema – viele Begriffe
Roboterjournalismus, algorithmischer Journalismus oder automatisierter Journalismus – wer sich mit dem Thema befasst, wird unter verschiedenen Schlagworten fündig. Immer jedoch ist jene Art von Nachrichtenproduktion gemeint, bei der Algorithmen aus Datenbanken und -kolonnen fertige Texte erstellen. Es liegt auf der Hand, dass damit vor allem Fakten basierter Journalismus forciert werden kann, bei dem die Texterstellung wiederholt einem bestimmten Muster folgt und in großer Menge verfasst werden muss. Deshalb setzen weltweit gesehen auch immer mehr Medienunternehmen für ihre Finanz-, Sport- und Chronikberichterstattung auf die Technologie, die als Natural Language Generation (NLG) bezeichnet wird und eine Subdomain von Artifical Intelligence ist.
Dass sich computergenerierte Texte in diesen Genres kaum mehr von journalistisch geschriebenen unterscheiden müssen, zeigt dieses Beispiel, das uns von AX Semantics zur Verfügung gestellt wurde.

Die New York Times hat für alle jene, die es selbst testen wollen, ein Quiz mit fünf Beispielen zusammengestellt. Die Ergebnisse sind teilweise überraschend.
Glaubwürdige Computertexte
Interessant ist in diesem Zusammenhang, dass Nutzer bei der Beurteilung der Texte diesen oft mehr Glaubwürdigkeit zubilligen, wie eine gemeinsame Studie der Ludwig Maximilian Universität in München, der Hochschule Macromedia und des Fraunhofer Instituts für Kommunikation, Informationsverarbeitung und Ergonomie mit knapp 1.000 Teilnehmern herausfand. Die Forscher rund um Andreas Graefe zeigten zudem auch, dass Leser vor allem dann computergenerierte Texte mögen, wenn sie nicht ahnen, dass diese von einem Algorithmus erstellt wurden. Eine ähnliche Studie von Christer Clerwall von der schwedischen Karlstadt Universität – wenn auch mit weitaus geringerem Sample – kam bereits 2014 zu einem ähnlichen Ergebnis.
Die Potenziale der Technologie
In Zeiten, wo Redaktionen personell immer weiter ausgedünnt werden, die Anforderungen der Kunden und Leser aber potenziell steigen, sind Medienunternehmen stetig auf der Suche, wie sie ihre Prozesse bei der Content-Erstellung optimieren können. Die Bandbreite der Überlegungen reicht dabei von der Unterstützung der Redakteure in der Aggregation von Daten bis zur vollautomatisierten Produktion von Texten.
Wie NLG die Verlage konkret unterstützen kann, brachte Saim Alkan, Geschäftsführer von AX Semantics, in einem Expertengespräch in der APA auf den Punkt.
Personalisierung: Inhalte können individualisiert werden
In Zukunft können durch die Kombination von strukturierter Erfassung mit Nachrichten- und Kundendaten immer besser auf den Nutzer zugeschnittene Einzeltexte generiert werden. Auf diesem Weg lassen sich bald individualisierte Nachrichten- oder E-Commerce-Seite erstellen.
Versionierung: Eine Ausgangsbasis – viele Texte
NLG-Software ist in der Lage, auf Knopfdruck viele verschiedene Versionen eines Textes zu erstellen. Damit kann das Dilemma von „Duplicated Content“ umgangen werden, der von den Suchmaschinen abgestraft wird. Auch die Tonalität kann für das jeweilige Medium bzw. demografische Gruppen optimiert werden. Und sogar unterschiedliche Plattformen (Web, Mobile) eines Mediums könnten so mit passenden Angeboten bedient werden.
Long Tail: Angebote für die Nische
Derzeit ist es aus Kostengründen oft nicht wirtschaftlich, thematische oder lokale Nischen zu bedienen. Im Sportbereich werden im Fußball etwa nur die großen Ligen gecovert, obwohl die Daten für eine Vielzahl an Sportarten vorhanden wären. NLG ermöglicht hier eine gut aufbereitete Berichterstattung, die User-Interessen in weit größerem Ausmaß als bisher bedienen kann.
Schnelligkeit: Texte im Sekundentakt
Texte können innerhalb von wenigen Sekunden erzeugt und verschickt werden.
Internationalisierung: Sprachbarrieren überwinden
Anbieter von NLG-Software bieten ihren Kunden die Möglichkeit, ihre Inhalte in mehreren Sprachen zu erzeugen. Das Computerprogramm generiert die jeweiligen Texte direkt in der gewünschten Zielsprache ohne den Umweg über eine andere Sprache. Kostspielige Übersetzungen können so entfallen.
Selbstoptimierende Inhalte
Bezieht man performanceorientierte Daten in die NLG-Software ein, kann sich der Prozess der Textautomatisierung selbst trainieren und verbessern.
“Only with automation does it make sense to make a thousand versions of a story that are specifically targeted to individual audience members, rather than producing one story for a large audience.”
James Kotecki, AP’s Head of Communications
Knackpunkte und Limitationen
In seinem vielbeachteten “Guide to Automated Journalism” für das Tow Center of Journalism, der Anfang 2016 publiziert wurde, macht Andreas Graefe sehr anschaulich auf die Restriktionen aufmerksam, denen die automatisierte Texterstellung derzeit unterliegt. Diese decken sich im Wesentlichen mit den Erkenntnissen, die auch Konstantin Dörr, Forscher am IMPZ der Universität Zürich, im APA-Medialab Gespräch festhielt.
Datenverfügbarkeit und -qualität
Für den journalistischen Bereich werden hochqualitative, verlässliche Daten in strukturierter und maschinen-lesbarer Form benötigt. Überall dort wo die Datenqualität schlecht oder die Verfügbarkeit nicht gewährleistet ist z.B. User Generated Information, niedriger Service Level bei Open Data, können die Ergebnisse verfälscht werden.
Validierung
Algorithmen können zwar Korrelationen herstellen, aber nicht Kausalitäten erklären. Daher können nur Fakten berichtet werden, aber nicht warum bestimmte Dinge passieren. Die klassischen Tugenden des Journalismus: Einordnung und Kontextualisierung sind weiterhin dem Menschen vorbehalten.
Qualitätssicherung
ist nur schwer zu bewerkstelligen. Es kann nicht mehr jeder Text gemonitort werden. Das kommt vor allem dort zum Tragen, wo die Technologie nicht als Tool im Newsroom genutzt wird, sondern als Ersatz für den Menschen, etwa durch die massenhafte Generierung zusätzlicher Texte.
Narration
NLG ist derzeit noch am Beginn, schön geschriebene längere Texte können also noch nicht erwartet werden. Hier wird sich aber in den nächsten Jahren viel verbessern.
Auswirkungen im Newsroom
Journalistische Artikel, die sich mit dem Thema befassen, werden nicht müde zu betonen, dass der Computer einen Journalisten nicht ersetzen könne. Und auch Forscher wie Konstantin Dörr oder der Hamburger Journalistik-Professor Thomas Hestermann in diesem Interview von Meedia bestätigen das. Im besten Fall arbeiten Mensch und Maschine zusammen.
“The future ofOnly with automation does it make sense to make a thousand versions of a story that are specifically targeted to individual audience members, rather than producing one story for a large audience.”
“The future of computational journalism and automation will and should be a collaborative one, where you have machines and people working together in a very conversational way.”
Alexis Llyod, NY Times R&D Lab creative director
Um automatisierte Texte erstellen zu können, benötigt man drei Komponenten: Daten, Textbausteine und eine Verknüpfung. Für die Produktion der Textbausteine sind in jedem Fall die Redakteure zuständig. Und zwar am besten Redakteure, bei den sich journalistische Fähigkeiten mit strukturiertem, mathematischem Denken paaren, wie Dörr erklärt. Sie sorgen dafür, dass unterschiedlichste Textbausteine zu ein und demselben Ergebnis erzeugt werden und Spielverläufe in einem Fußballspiel modelliert werden können. Da fallen für die Kategorie Fußball schon bis zu 300 Varianten an, wusste Helen Vogt von der norwegischen Nachrichtenagentur NTB beim letzten GEN Summit im Juni 2016 zu berichten. Einmal geschrieben können die Textbausteine vom Computer jederzeit beliebig variiert werden. Liegen dann noch gute Ankerpunkte vor z.B. historische Auffälligkeiten, ein Fokus auf bestimmte Spieler oder auf Regionalität (Spieler- und Vereinsdatenbank) können weitere Facetten erzeugt werden.
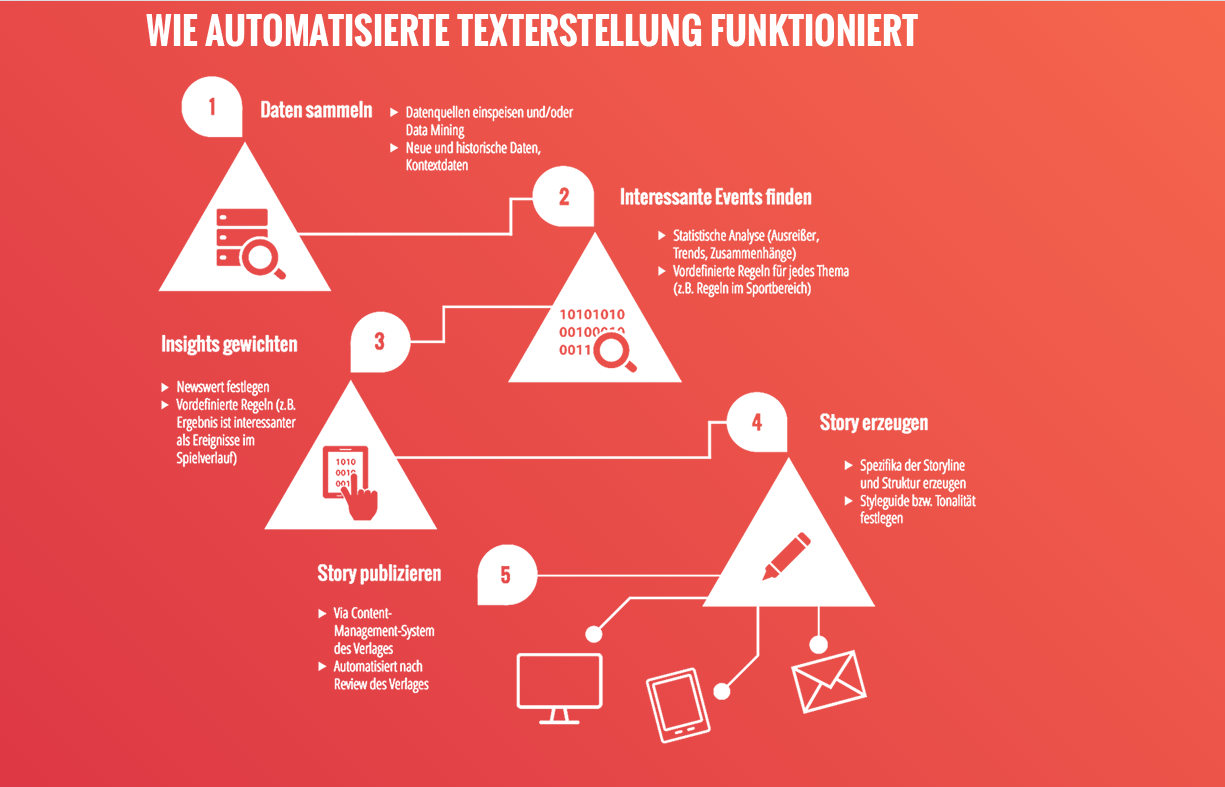
Kritische Fragestellungen
Journalisten werfen in diesem Zusammenhang jedoch zu Recht auch einige kritische Fragen auf, wie die Studie „When Reporters get hand-on with robo-writing“, die Anfang März 2017 in der internationalen Peer-Review-Fachzeitschrift Digital Journalism erschienen ist, und uns von Konstatin Dörr zur Verfügung gestellt wurde, zeigt. Darin konnten Journalisten, unter anderem der CNN, BBC oder Reuters, die Technologie ausprobieren. Drei Punkte fallen hier besonders ins Auge:
- Berichterstattung auf einzelne, isolierte Datensets zu stützen ist aus journalistischen Gesichtspunkten schwierig.
- Templates für Unvorhergesehens zu schreiben, ist nahezu unmöglich.
- Oft liegt die Herausforderung die Geschichte in den Daten zu erkennen und nicht aus den Daten eine Geschichte zu machen.
Dass die gute journalistische Geschichte oft gar nicht aus den faktenbasierten Daten entsteht, sondern aus Geschehnissen vor Ort oder durch Interviews ist eine weitere Komponente, die in diesem Zusammenhang noch ungelöst ist. Roboter-Journalismus spielt für die Forscher aus diesen Gründen vor allem da eine große Rolle, wo Journalisten nicht verdrängt werden, sondern wo sie noch gar nicht gearbeitet haben.
“If you believe that your job as a journalist is to enhance public knowledge and enrich civic life, then I think you should realize writing is simply one of the tools you have at your disposal.”
Andrew DeVigal, endowed chair in journalism innovation and civic engagement at the University of Oregon
Daten als das neue Öl
Im Rahmen von Automatisierungsprojekten ist neben der Textbaustein-Erstellung jedoch noch ein weiteres Handlungsfeld für Verlage essenziell: die Erstellung und der Betrieb von Datenbanken, deren Themengebiete sich für die Automatisierung eignen. Hier kommen je nach Einsatzgebiet redaktionell geschultes Personal zum Einsatz oder Mitarbeiter aus anderen Verlagsbereichen, die für die Erfassung der Daten, z.B. Events, zuständig sind. Oder aber der Verlag stellt Dritten Templates für die Erfassung von Daten zur Verfügung und verarbeitet diese dann im Haus weiter. Dies ist vor allem im Sportbereich interessant. Experten sind sich einig, dass diejenigen, die Datenbanken betreiben und pflegen in Zukunft mehr und – bei algorithmusgetriebener Interpretation – auch wesentlich komplexere “Roboterberichterstattung” durchführen können als bisher.
Einsatzgebiete von automatischer Texterstellung im Medienbereich
Analysiert man die derzeit bekannten, aber auch in den Gesprächen mit uns genannten noch nicht öffentlich kommunizierten Beispiele so kristallisieren sich unterschiedliche Einsatzgebiete von NLG im Medienbereich heraus. Die Mehrheit fokussiert dabei auf die Berichterstattung, es lassen sich aber auch für andere Geschäftsbereiche Anwendungen finden.
Berichterstattung
- Sport: z.B. Fußballergebnisse
- Sicherheit: z.B.: Verbrechen-Reports
- Finanzen & Wirtschaft: z.B. Börse-Reports, Geschäftsberichte
- Society: z.B. Prominews
- Politik: z.B. Wahlergebnisse, Wahlprognosen
Servicemeldungen
- Umwelt: z.B. Wetterberichte, Feinstaub-Updates
- Verkehr: z.B. Staumeldungen, Ankündigung von Straßensperren
- Termine: z.B. Eventankündigung
- Branchenbuch: z.B. Firmendarstellungen
E-Commerce
- Textierung von Angeboten in verlagseigenen Online-Shops
- Verknüpfung von Berichterstattung und kommerziellen Datenbanken z.B. aus dem Segment Essen&Trinken
Zukünftige Einsatzgebiete laut Expertengesprächen
- Berichterstattung: Musik- und Buchvorstellungen
- Serviceinhalte: TV-Programm, Horoskope, Ausgehtipps
- Classifieds: Textierung von Inseraten
- Verlagsmarketing: Erstellung von individuellen Briefen für Abonnenten
- Neuartige Zusatzservices: Applikationen für Haus & Garten z.B. User geben Profil ihres Gartens ein (m2, Lage etc.) – App macht auf Basis von Geodaten und Wetter Vorschläge zu Aktivitäten und Gestaltung rund um das Gartenjahr
Use Cases: Externe und interne Datenbanken verwerten
Schon lange sind Medien in der Berichterstattung auf externe und interne Datenquellen angewiesen. Diese werden in unterschiedlichen Formaten verarbeitet: in datenjournalistischen Projekten, in Grafiken oder Tabellen und seit einiger Zeit auch im Bereich der Automatisierung. Die Daten liegen dabei in den vielfältigen Formaten vor und lassen sich selten 1:1 übernehmen, weshalb sie für den journalistischen Gebrauch meist aufbereitet werden müssen. Im Folgenden zeigt ein Überblick anhand von exemplarischen Use Cases welche Daten derzeit verwendet werden.
Externe Sensordaten als Quelle
Erste Gehversuche im Bereich automatisierter Texterstellung bei etablierten Medien wurden bereits 2014 unternommen. So erzeugte die Los Angeles Times mit Hilfe des Quakebot Erdbebenberichte. In Deutschland startete die Berliner Morgenpost den Feinstaub-Monitor, der die Luftgütemessungen des Umweltbundesamtes auswertete.
Rasch zeigte sich, dass Sensordaten – allen voran Wetterdaten – besonders geeignet sind, um automatisierte Texte zu verfassen. Eine Reihe von deutschsprachigen Portalen wie Meinestadt.de textiert seine Wetterprognosen mittlerweile auf Basis der gelieferten Wetterdaten. Wie aus Wetterdaten eine Meldung entsteht, ist hier anhand eines Beispiels beschrieben.

Das Potenzial der Verwertung von Sensordaten steht erst am Anfang. So evaluiert derzeit das deutsche Forschungsprojekt Newstream 3.0 unter Führung des Fraunhofer-Instituts für Intelligente Analyse- und Informationssysteme IAIS inwieweit sich aus der Beobachtung der Pegelstände großer deutscher Flüsse, verwertbare Ergebnisse für die Berichterstattung ablesen lassen. Und auch im Rahmen der Google Digital News Initiative werden aktuell Projekte gefördert, die den Einsatz von Sensordaten für die Entwicklung neuer Produkte erforschen.
Sportdaten einbinden
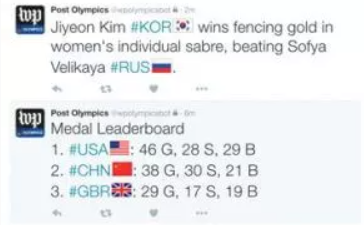
Im Sportbereich existieren zahlreiche Lieferanten, welche die gewünschten Daten sehr granular bereitstellen können. Lediglich auf lokaler Ebene versiegt der Zahlenstrom oft, weshalb hier Nischenportale oder Medienunternehmen selbst aktiv werden müssen, um eine Berichterstattung zu gewährleisten. Ob ein Medium auf externe oder interne Quellen setzt, liegt daher ganz daran, ob es bereits eigene Sportdatenbanken aufgebaut hat und ob es eine lokale, regionale oder überregionale Leserschaft bedient.
Die Use Cases reichen international gesehen von den Live-Analysen von NFL-Spielen durch den 4th Down Bot der New York Times über die automatisierte Berichterstattung der Washington Post rund um die olympischen Sommerspiele 2016 auf Basis des selbstentwickelten Software Heliograph bis hin zur Online-Tochter des Weser Kurier, die für das Portal Sportbuzzer automatisierte Spielberichte aus Fußball-Amateurligen verfasst.
Auch Nachrichtenagenturen sind in diesem Feld aktiv. Konkret stellen die amerikanische AP, die norwegische NTB, die britische PA und die australische AAP eigens gekennzeichnete Agenturströme meist zum Lokal- und Amateursport zur Verfügung.
Wie Fußballberichterstattung auf Basis eines selbst gepflegten Datenkatalogs zu den Spielen aussehen kann, zeigt dieses Beispiel der Nordwestzeitung, die im Rahmen einer Kooperation dem FuPa-Portal Texte zur regionalen Fußballberichterstattung liefert.
# Ein 2:1-Ergebnis für den Süderneulander SV ## Ostfrieslandliga: Partie Süderneulander SV vs. BSC Burhafe, Datum: 12.03.2017, Uhrzeit: 15:00
In der Ostfrieslandliga kam es am 24. Spieltag zum Match zwischen Süderneulander SV und BSC Burhafe. Die Partie endete mit 2:1 für Süderneulander SV. In der 28. Minute ging der BSC Burhafe in Führung. Torschütze war Tobias Taddicken. In der 59. Minute folgte das 1:1 durch Marco Peters für Süderneulander SV. In der 76. fiel ein weiteres Tor durch Johannes Yalcin. Dies war der Treffer zum 2:1. Die Hausherren mit Trainer Matthias Hauptmann stehen mit 32 Punkten aktuell auf Position sechs in der Tabelle. Unter Trainer Olaf Link belegen die Gegner mit 18 Zählern Tabellenplatz 14.
Hört man sich in der Branche um, dann werden demnächst noch zahlreiche weitere Projekte von deutschsprachigen Medienhäusern im Sportbereich gelauncht werden.
Die neue Technologie hilft aber auch Branchenfremden medienähnliche Portale aufzusetzen. Bereits in den Startlöchern für den Beta-Start seines Portals steht Sportnachrichten.at, das von Wolf Galetzki, einem Consultant im Bereich automatisierte Texterstellung, als „Showcase für das, was heute möglich ist“, aufgesetzt wurde. Monetarisierungsphantasien gäbe es derzeit keine, meinte Galetzki auf Nachfrage des APA-Medialab. Gestartet werde mit Fußball, danach könnten noch weitere Sportarten dazu kommen.
Finanzdaten auswerten
Die von der Börse getriebene Berichterstattung kann traditionell auf vielfältige Datensets zurückgreifen, benötigen Finanzmanager doch am besten Real-Time-Daten, um ihre Entscheidungen bezüglich Käufe und Verkäufe treffen zu können. Dieser Quelle bedienen sich Medien wie Forbes, die auf dieser Basis Nachrichten aus Echtzeitfinanzdaten erzeugt oder auch Focus Online für die Produktion von automatisierten Texten bei Finanzen100. Für Nachrichtenagenturen wie AP, die dänische Ritzau, die amerikanisch Bloomberg und PA ist dieser Use Case meist der Einstieg in die Materie.

Wahldaten regionalisieren
Wenn Wähler zur Urne schreiten, sind Medienunternehmen in punkto rasche Datenverwertung besonders gefordert. Immer später werden Ergebnisdaten zur Verfügung gestellt, die immer schneller möglichst regional für die Öffentlichkeit aufbereitet müssen. Ein gutes Einsatzgebiet für automatisierte Texterstellung, vor allem für Nachrichtenagenturen, wie Pilotprojekte bei Reuters und der britischen Press Association zeigen.
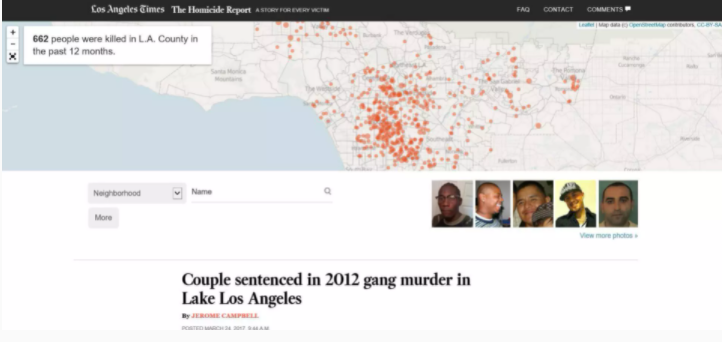
Chronikdaten erfassen
Auf einer eigens entwickelten Datenbank setzt der Homicide Report der Los Angeles Times auf, auf Basis dessen Crime-Alerts für jene Bezirke produziert, in denen die Verbrechensrate eine bestimmte Schwelle überschreitet. Dieses Projekt ist ein guter Show Case dafür, wie Datenjournalismus und automatisierte Texterstellung sich sinnvoll ergänzen können.
Verwertung weiterer hauseigener Datenbanken
Doch auch andere Bereiche, für die es bisher keine Texte gibt, eignen sich für die Verbesserung der Servicequalität der erbrachten Dienstleistung. So erzählt Victor Deditius, Produktmanager Online bei der deutschen “Nordwestzeitung”, im APA-Medialab-Gespräch, dass man die Technologie auch für Eventbeschreibungen auf dem Terminportal des Medienhauses einsetze oder für Firmenbeschreibungen im Branchenbuch.
Die Anwendungen im journalistischen Bereich seien diesen Projekten gefolgt. Auch deshalb weil Ende 2015, als das Medium das Pilotprojekt im Bereich Automatisierung startete, die Bedienbarkeit der Tools noch gewöhnungsbedürftig war. Das habe sich sehr verbessert und Journalisten könnten damit jetzt gut umgehen.
Nachrichtenagenturen als Profiteure
Zahlreiche Nachrichtenagenturen weltweit experimentieren mit automatisierter Texterstellung bzw. bieten bereits eigene Agenturdienste an, die von einer Software erzeugt wurden. Welche Erfahrungen damit gemacht wurden, wo die Herausforderungen aus Sicht der Nachrichtenagenturen liegen und wie NLG der Agenturalltag verändern kann, erforscht derzeit gerade APA-Redakteur Alexander Fanta im Rahmen eines “Google Digital News Fellowship” am Reuters Institut in Oxford. Ihm zufolge produziert bei Agenturen die eingesetzte Software fast immer neue Produkte oder weitet die bisherige Berichterstattung drastisch aus, etwa zu Regionalsport oder Detail-Wahlergebnistexten für jede Gemeinde. Seine Forschungsergebnisse werden wir ab Juni 2017 hier zur Verfügung stellen.
IT-Dienstleister für automatisierte Texterstellung
Die Entwicklung von hauseigener Software wird wohl in Zukunft einigen wenigen großen Medienhäusern vorbehalten bleiben. Denn neue Erkenntnisse im Bereich Artifical Intelligence lassen sich nur von spezialisierten IT-Abteilungen am Puls der Zeit vorantreiben. Alle anderen werden ihre ersten Schritte in der automatisierten Textproduktion mit der wachsenden Schar an Dienstleistern in diesem Bereich wagen. Derzeit bieten unseres Wissens 15 Unternehmen, davon zwei in den USA (Automated Insights, Narrative Science), fünf in Deutschland (Retresco, AX Semantics, Textomatic, Text-On, 2txt), zwei in Frankreich (Syllabs, Labsense) und je eines in Großbritannien (Arria), in China (Tencent), in Russland (Yandex), in Bulgarien (Identrics), in Norwegen (Oribt.ai) und in Israel (Articoloo) Medienunternehmen ihre Unterstützung an.
Der fachliche Background der Unternehmen ist sehr unterschiedlich. Während die einen z.B. Narrative Science oder Arria aus dem universitären Umfeld stammen, haben andere wie Retresco oder Identrics ihren Ursprung in der Datenbanktechnologie und Dritte wie AX Semantics sind aus einer Textagentur hervorgegangen. Wurde lange Zeit nur auf Kundenwunsch programmiert, so tendieren die Unternehmen jetzt zu Self Service Anwendungen. Arria und Automated Insights haben ihre Plattformen bereits für Entwickler in Medienhäusern geöffnet, AX Semantics lehrt seine Programmiersprache auf Hochschulen.
Neben den genannten Anbietern gibt es noch eine Reihe weiterer Unternehmen, die im Bereich der automatisierten Texterstellung tätig sind, wie Smartologic, Linguasta oder Yseop. Sie haben allerdings keine Referenzen im Mediensektor.
Ausblick
Wer einen Blick in die Zukunft wagen will, dem seien die acht Thesen von Alexander Siebert, Geschäftsführer von Retresco, empfohlen. In diesem Artikel für die Huffington Post erläutert Siebert, der sich gerne als Experte für die Automatisierung Content getriebener Geschäftsmodelle bezeichnet unter anderem warum bis 2020 der gesamte Journalismus datengetrieben sein wird.
Dass es dabei längst nicht nur um die Produktion von Texten gehen wird, zeigt das britische Marketing-Magazin „The Drum“, das IBMs Superhirn Watson jüngst für eine Ausgabe als Chefredakteur engagierte. Watson wählte Bilder aus, passte Texte an und gestaltete die Seiten. Dafür wurde der Computer mit Daten der Gewinner des Goldenen Löwen beim Cannes Lions International Festival of Creativity gefüttert. Das Ziel war es, eine kreative Künstliche Intelligenz zu schaffen. Wir werden sehen, wann die Marketing-Experimente zum Alltag in den Newsrooms werden.

Weiterführende Links
Für die Erstellung dieses Biefings wurde ein Vielzahl von Studien, journalistischen Artikeln und akademischen Research Papers gesichtet sowie Expertengespräche geführt. Eine Auswahl an lesenswerten Beiträgen ist hier verlinkt.
Keine Angst vor Roboter-Reportern (Zeit Online, 20. Februar 2017)
Guide to Automated Journalism (Andreas Graefe, Studie für das Tow Center for Digital Journalism, 07. Jänner 2016)
AI is already making inroads into journalism but could it win a Pulitzer? (The Guardian, 3. April 2016)
Nieman Reports: Automation in the Newsroom. (01. September 2015)