- Managed Services
- Lösungen
- Managed Services
Wir übernehmen Datensicherung und IT-Infrastruktur für Sie
- Disaster Recovery
Sensible Geschäftsdaten für den Fall der Fälle geschützt
- Managed Services
- Produkte
- Container-Plattform
Container-Plattform von APA-Tech mit NetApp, F5 & Red Hat
- Object-Storage
Die Datenspeicherlösung von APA-Tech
- NetApp Container-Storage
Mit NetApp Trident behalten Sie die Kontrolle über Container-Daten
- Rechenzentren
Sichere und lokale Datenhosting-Lösungen in Wien
- Observability-Plattform
Echtzeitüberwachung Ihrer IT-Systeme
- Container-Plattform
- Produkte
- Security as a Service
Schützen Sie Ihr Unternehmen vor Cyberbedrohungen
- VMware by Broadcom
Wir sind Ihr Partner für VMware by Broadcom.
- Housing und Hosting
Hochverfügbare und ausfallsichere IT-Infrastruktur mit 24/7-Support
- Outsourcing
Wir planen und übernehmen Ihre Unternehmens-IT
- Security as a Service
- Blogbeiträge
- Tech-Blog
Neuigkeiten aus der IT-Welt
- Tech-Blog
- Lösungen
- Content publizieren
- Lösungen
- Services für Marketingverantwortliche
vereinfacht Ihre Contentproduktion
- Services für Marketingverantwortliche
- Produkte
- VideoService
Vom Standard-Streaming bis zum individuellen Produktions-Workflow
- Mobile Publishing Suite
Ihre Publikationen als App über Tablets und Smartphones
- VideoService
- Lösungen
- Customizing & Consulting
- Produkte
- Austria Videoplattform
Hochqualitativer und aktueller News-Content im Videoformat
- PR-Desk
Verbreiten, Beobachten und Recherchieren in einem Tool
- Austria-Kiosk
Digitaler Zeitungsstand mit über 400 Zeitungen und Magazinen
- APA-NewsDesk
Medien - & Datenhub
- Austria Videoplattform
- Produkte
- Karriere
Language Bias in Multilingual Semantic Search Systems
In the fast-changing field of natural language processing (NLP), semantic search has become crucial for applications like chatbots and fact-checkers. This technology can also enhance search engines, allowing users to find relevant information by asking questions in natural language. Embedding models are central to this, converting text into high-dimensional vectors that capture the meanings of words and phrases. This helps computers find the most relevant information by comparing similar vectors.
APA has a year of experience fine-tuning these models to ensure relevant content retrieval, especially in the fast-paced news industry. In collaboration with the G39 group of European news agencies and Cloudflight, APA is developing a multilingual semantic search system. This system will allow users to retrieve relevant news in nine languages by querying in any language, making it easier to stay informed of reporting across different news agencies.
However, multilingual semantic search isn’t limited to news; it can also be useful in areas like international e-commerce or booking platforms. However, creating a truly multilingual system is challenging because models often prioritize results in the query’s language. In this blog post, we aim to highlight this issue, explain it, and discuss how we mitigated it.
What is Language Bias?
Language bias occurs when multilingual semantic search systems prioritize results in the same language as the user query over results in other languages, even if the latter are more relevant. This bias is problematic, especially when the answer to a query is not available in the query language but exists in another language. In such cases, the system may return many irrelevant texts in the query language before showing the relevant ones in a different language. The term language bias was coined by Roy et al. (2020) in the paper LAReQA: Language-agnostic answer retrieval from a multilingual pool [1]. The authors define cross lingual alignment and describe two scenarios – weak and strong alignment:
-
- „Weak Alignment: For any item in language L1, the nearest neighbor in language L2 is the most semantically relevant item.
- Strong Alignment: For any item, all semantically relevant items are closer than all irrelevant items, regardless of their language. Crucially, relevant items in different languages are closer than irrelevant items in the same language.„
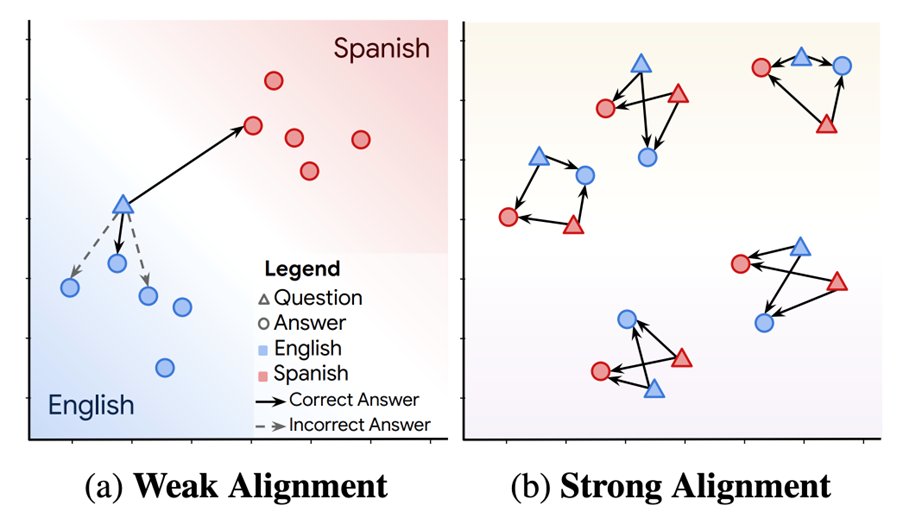
Weakly aligned multi-lingual embedding models work well, when we want to use the same embedding model for each language content separately (e.g. I only want to host one embedding endpoint but have many content databases in different languages) or when I want to search in my language (e.g. German) in a French content database without translating the query.
However, if you need to perform semantic search in a content databsesdatabase containing texts in different languages, only models with strong alignment will produce results that are free of language bias, thus making sure that the most relevant candidates are ranked highest and not the ones matching the query language.
Visualization of the embedding space
An easy way of detecting the presence of language bias in a multilingual model is to visualize the embeddings of a set of parallel sentences in two languages in 2D. That might look as follows, where the left diagram visualizes embeddings of intfloat/multilingual-e5-large, a very popular multilingual open-source model with language bias and the right one those of a custom fine-tune of it that is well aligned.
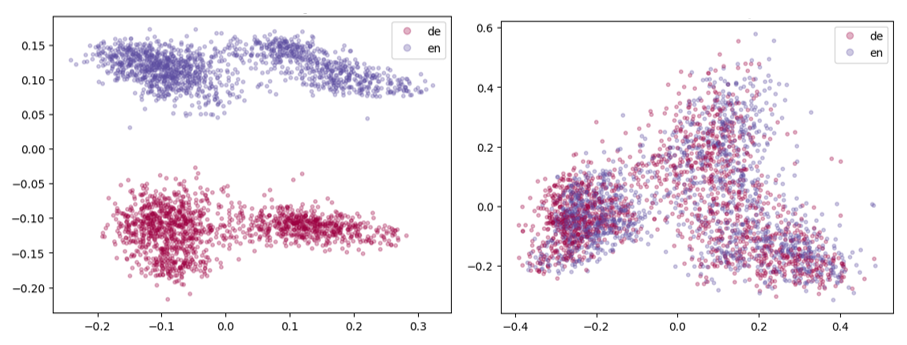
The diagrams show the data distribution in the model, where German data is shown in red and English data in blue. On the left side we can see that language is greatly influencing the embedding distribution. No overlap between the colors means that there is a language bias. The right diagram shows blue and red points well interleaved, which means English and German embeddings map to the same semantic space. Beware that this visualization technique is only an illustrative starting point and does not allow us to quantify the degree of alignment.
How to measure it?
To quantify and compare the language bias of different models, you can follow one of these approaches:
1. Evaluate your model on the LAReQA dataset as described in the paper LAReQA: Language-agnostic answer retrieval from a multilingual pool by Roy et al [1]. Besides a method for quantifying the bias, the paper proposes a useful heatmap visualization where you can see the degree of alignment between all language pairs. On the downside, the LAReQA dataset does not consist of a lot of languages.
2. Using an approach from the paper Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation by Nils Reimers and Iryna Gurevych [2]. They propose to evaluate the model on a semantic textual similarity (STS) task using a multilingual STS dataset and see how much worse the model performs when you don’t test on every language individually but on a candidate set with all languages at once.
In addition to quantifiable measures, it’s also advisable to test for language bias manually. Select a couple of queries, translate them to different languages and issue a search for each translation. You should find approximately the same results for each translation of the same query. If you see results following the language of your query instead, you have a biased model without strong alignment.
Mitigating language bias
For the G39 project we built up large fine-tuning datasets from news articles from different countries to let the model learn different news contexts. Due to our experience with training mono-lingual embedding models we were confident that we could create a model that knows the current news context of multiple countries. A central question was whether this trained model is usable for multilingual semantic search. We researched and brainstormed many ideas, but the solution was surprisingly simple in the end: the baseline training approach produced satisfactory results already. That is, we merged our nine large monolingual finetuning datasets together into one consisting of queries and news article chunks in nine different languages (but each query-article-pair still used only language). Training on this dataset using a standard contrastive loss with in-batch negatives eliminated most of the language bias that we measured and negatively noticed in the base model.
Why does this work? We are still in the process of finding out, but we can already share insights:
- having a large amount of high-quality multilingual fine-tuning data at our disposal, and
- having a considerable topic overlap between the different languages in the dataset, because a good part of the news is international.
We nicknamed our approach “brute-force mitigation”, since obviously having a large high-quality amount of training data did the trick. That being said, if you don’t have large amounts of multilingual finetuning data at hand but maybe just data in one language, the approach from Reimers and Gurevych [2] may be worth taking a look at. The paper explains how to extend the capabilities of an existing embedding model to new languages with a training objective that targets equal embeddings in all languages (i.e. strong alignment).
References:
[1] LAReQA: Language-agnostic answer retrieval from a multilingual pool https://arxiv.org/abs/2004.05484
[2] Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation https://arxiv.org/pdf/2004.09813
About Cloudflight
Das könnte Sie auch interessieren
Produkt
VideoService
Verwalten und bearbeiten Sie Ihre Livestreams und Videos einfach und effizient und spielen Sie diese auf allen Endgeräten & Betriebssystemen aus.
Innovation
Verifikation von digitalen Fotos und Videos
Manipuliertes Bildmaterial in sozialen Medien stellt den Journalismus vor eine große Herausforderung. Mithilfe zahlreicher digitaler Tools können derartige Informationen allerdings oft verifiziert werden.
Produkt
Eventfotografie
Professionelle Fotografinnen und Fotografen und mediale Verbreitung aus einer Hand: APA-Fotoservice setzt Ihre Veranstaltung gekonnt und umfassend in Szene.