- Managed Services
- Lösungen
- Managed Services
Wir übernehmen Datensicherung und IT-Infrastruktur für Sie
- Disaster Recovery
Sensible Geschäftsdaten für den Fall der Fälle geschützt
- Managed Services
- Produkte
- Container-Plattform
Container-Plattform von APA-Tech mit NetApp, F5 & Red Hat
- Object-Storage
Die Datenspeicherlösung von APA-Tech
- NetApp Container-Storage
Mit NetApp Trident behalten Sie die Kontrolle über Container-Daten
- Rechenzentren
Sichere und lokale Datenhosting-Lösungen in Wien
- Observability-Plattform
Echtzeitüberwachung Ihrer IT-Systeme
- Container-Plattform
- Produkte
- Security as a Service
Schützen Sie Ihr Unternehmen vor Cyberbedrohungen
- VMware by Broadcom
Wir sind Ihr Partner für VMware by Broadcom.
- Housing und Hosting
Hochverfügbare und ausfallsichere IT-Infrastruktur mit 24/7-Support
- Outsourcing
Wir planen und übernehmen Ihre Unternehmens-IT
- Security as a Service
- Blogbeiträge
- Tech-Blog
Neuigkeiten aus der IT-Welt
- Tech-Blog
- Lösungen
- Content publizieren
- Lösungen
- Services für Marketingverantwortliche
vereinfacht Ihre Contentproduktion
- Services für Marketingverantwortliche
- Produkte
- VideoService
Vom Standard-Streaming bis zum individuellen Produktions-Workflow
- Mobile Publishing Suite
Ihre Publikationen als App über Tablets und Smartphones
- VideoService
- Lösungen
- Customizing & Consulting
- Produkte
- Austria Videoplattform
Hochqualitativer und aktueller News-Content im Videoformat
- PR-Desk
Verbreiten, Beobachten und Recherchieren in einem Tool
- Austria-Kiosk
Digitaler Zeitungsstand mit über 400 Zeitungen und Magazinen
- APA-NewsDesk
Medien - & Datenhub
- Austria Videoplattform
- Produkte
- Karriere
Language-Bias in der Suche von mehrsprachigen Inhalten
Die Verarbeitung natürlicher Sprache (NLP) entwickelt sich rasant weiter, wobei die semantische Suche für Tools wie Chatbots essenziell ist. Sie ermöglicht es Nutzer:innen, mittels natürlicher Sprache relevante Informationen zu finden. In Kooperation mit der G39-Gruppe europäischer Nachrichtenagenturen und Cloudflight entwickelt die APA eine mehrsprachige semantische Suche, die es ermöglicht, in neun Sprachen relevante Nachrichten zu recherchieren.
Im sich schnell wandelnden Bereich der Verarbeitung natürlicher Sprache (NLP) ist die semantische Suche für Anwendungen wie Chatbots und Faktenprüfer von entscheidender Bedeutung. Diese Technologie verbessert Suchmaschinen, indem sie es Nutzer:innen ermöglicht, relevante Informationen durch Suchabfragen in natürlicher Sprache zu finden. Sogenannte Embedding-Modelle spielen dabei eine zentrale Rolle, indem sie Texte in hochdimensionale Vektoren umwandeln, die die Bedeutungen von Wörtern und Phrasen erfassen, anstatt nach Keywords zu suchen. Dies hilft Computern, die relevantesten Informationen zu finden, indem sie ähnliche Vektoren vergleichen.
Die APA beschäftigt sich seit einem Jahr mit der Feinabstimmung (fine-tuning) dieser Modelle, um sicherzustellen, dass immer die relevantesten Inhalte gefunden werden. In Zusammenarbeit mit der Gruppe39, eine Initiative unabhängiger, europäischer Nachrichtenagenturen und Cloudflight entwickelt APA eine mehrsprachige semantische Suche. Diese Suche wird es Nutzer:innen ermöglichen, in ihrer eigenen Sprache Suchabfragen abzusetzen und dann alle dazu relevanten Nachrichten in neun Sprachen zu finden. Dadurch können Journalist:innen den gesamten Inhalt aller G39-Agenturen für Recherchen nutzen.
Eine mehrsprachige semantische Suche ist jedoch nicht nur auf Nachrichten beschränkt. Sie kann auch im internationalen E-Commerce oder im Bereich von Buchungsplattformen nützlich sein. Die Erstellung eines mehrsprachigen Systems ist aber eine Herausforderung, da die Modelle oft Ergebnisse priorisieren, die die gleiche Sprache haben, in der auch die Suchabfrage gemacht wurde. In diesem Blogbeitrag möchten wir auf diesen sogenannten “Language-Bias”, hinweisen und erörtern, wie wir den Bias reduzieren konnten.
Was ist ein Language-Bias?
Ein Language-Bias (auf Deutsch: Sprachliche Voreingenommenheit) tritt auf, wenn mehrsprachige semantische Suchsysteme Ergebnisse, die die gleiche Sprache wie die Suchabfrage haben, priorisieren – selbst wenn Ergebnisse in anderen Sprachen relevanter sind. Wenn man beispielsweise auf Deutsch sucht, bekommt man auch deutschsprachige Inhalte in den Top-Suchergebnissen angezeigt – und das, obwohl es passendere Ergebnisse in anderen Sprachen gibt. Dieser Bias ist gerade bei internationalen Themen problematisch. In solchen Fällen kann das System viele irrelevante Texte in der Abfragesprache zurückgeben, bevor es die relevanten Ergebnisse in einer anderen Sprache anzeigt. Der Begriff „language bias“ wurde von Roy et al. (2020) in dem Paper „LAReQA: Language-agnostic answer retrieval from a multilingual pool“ geprägt. [1] Die Autoren definieren sogenanntes cross-lingual alignment und beschreiben zwei Szenarien: Weak Alignment und Strong Alignment:
Weak Alignment: Für jeden Artikel in einer Sprache (bspw. Deutsch) ist der nächstgelegene Nachbar in einer anderen Sprache der semantisch relevanteste Artikel. Das bedeutet, dass weniger relevante Artikel in Deutsch näher liegen, als der relevanteste Artikel auf Englisch – dieser ist zwar der am nächsten liegende englische Artikel, wird aber hinter die weniger relevanten Nachbarn auf Deutsch zurück gereiht.
Strong Alignment: Für jeden Artikel sind alle semantisch relevanten Artikel näher als alle irrelevanten Artikel, unabhängig von ihrer Sprache. Entscheidender Weise sind relevante Artikel in verschiedenen Sprachen näher als irrelevante Artikel in derselben Sprache.
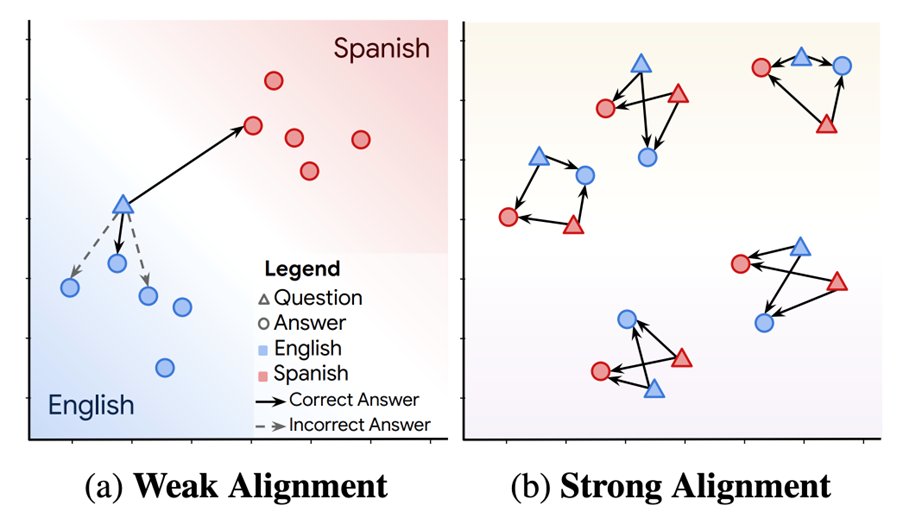
„Weak Alignment“ mehrsprachige Embedding-Modelle funktionieren gut, wenn dasselbe Embedding-Modell für jeden Sprachinhalt separat verwendet wird oder wenn in der eigenen Sprache (z. B. Deutsch) in einer französischen Inhaltsdatenbank gesucht wird, ohne die Abfrage zu übersetzen.
Wenn Sie jedoch eine semantische Suche in einer Inhaltsdatenbank durchführen, die Texte in verschiedenen Sprachen enthält, werden nur Modelle mit „Strong Alignment“ Ergebnisse liefern, die frei von Language-Bias sind. So wird sichergestellt, dass immer die relevantesten Ergebnisse am höchsten eingestuft werden – und nicht die, die mit der Sprache der Suchabfrage übereinstimmen.
Visualisierung des Embedding-Raums
Eine einfache Möglichkeit, das Vorhandensein von Language-Bias in einem mehrsprachigen Modell zu erkennen, besteht darin, die Embeddings von gleichen Sätzen (in zwei Sprachen und in 2D) zu visualisieren. In unserem Beispiel vergleichen wir einen deutschen mit einem englischen Satz. Das linke Diagramm zeigt die Embeddings von intfloat/multilingual-e5-large, einem sehr gängigen mehrsprachigen Open-Source-Modell mit Language-Bias. Das rechte Diagramm zeigt die Embeddings eines angepassten „Strong Alignment“-Modells.
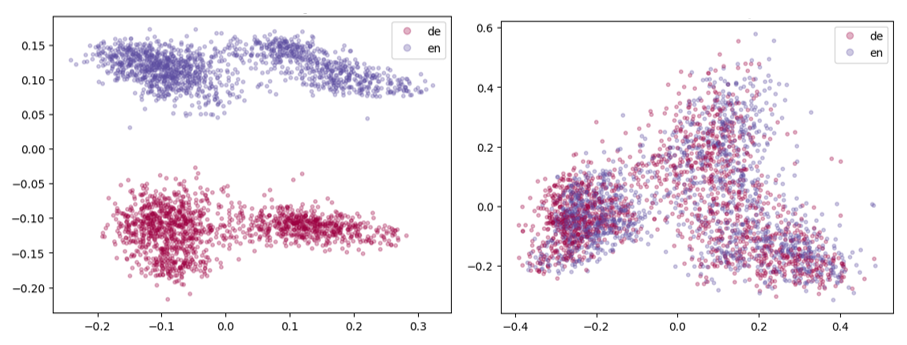
Die Diagramme zeigen die Datenverteilung im Modell, wobei deutschsprachige Daten in Rot und englischsprachige Daten in Blau dargestellt sind. Auf der linken Seite zeigt sich, dass die Sprache die Embedding-Verteilung stark beeinflusst. Keine Überlappung der Farben bedeutet, dass es einen Language-Bias gibt. Das rechte Diagramm zeigt, blau und rot gut durchmischt, was bedeutet, dass englische und deutsche Embeddings auf denselben semantischen Raum abgebildet werden.
Wie misst man einen Language-Bias?
Um den Language-Bias verschiedener Modelle zu quantifizieren und zu vergleichen, gibt es zwei Ansätze:
1. Evaluieren Sie Ihr Modell auf dem LAReQA-Datensatz, wie im Paper „LAReQA: Language-agnostic answer retrieval from a multilingual pool“ von Roy et al. beschrieben. Neben einer Methode zur Quantifizierung des Bias schlägt das Paper eine nützliche Heatmap-Visualisierung vor, in der Sie den Grad des „Alignments“ zwischen allen Sprachpaaren sehen können. Der Nachteil ist, dass der LAReQA-Datensatz aus wenigen Sprachen besteht.
2. Der zweite Ansatz ist aus dem Paper „Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation“ von Nils Reimers und Iryna Gurevych. [2] Sie schlagen vor, das Modell in einer semantischen Textähnlichkeitsaufgabe (STS) mit einem mehrsprachigen STS-Datensatz zu evaluieren und zu sehen, wie viel schlechter das Modell abschneidet, wenn man nicht jede Sprache einzeln testet, sondern einen Kandidatensatz mit allen Sprachen gleichzeitig.
Zusätzlich zu quantifizierbaren Maßnahmen ist es auch ratsam, den Language-Bias manuell zu testen. Denken Sie sich einige Suchabfragen aus, übersetzen Sie diese in verschiedene Sprachen und führen Sie für jede Übersetzung eine Suche durch. Sie sollten ungefähr die gleichen Ergebnisse für jede Übersetzung dieser Abfrage finden. Wenn Sie stattdessen Ergebnisse erhalten, die der Sprache Ihrer Abfrage folgen, haben Sie ein voreingenommenes Modell ohne „Strong Alignment“ vor sich.
Minderung des Language-Bias
Für das G39-Projekt haben wir große Datensätze aus Nachrichtenartikeln verschiedener Länder aufgebaut, um dem Modell zu ermöglichen, unterschiedliche Nachrichtenkontexte zu lernen. Aufgrund unserer Erfahrung mit der Ausbildung monolingualer Embedding-Modelle waren wir zuversichtlich, dass wir ein Modell erstellen können, das den aktuellen Nachrichtenkontext mehrerer Länder kennt. Eine zentrale Frage war, ob dieses trainierte Modell für die mehrsprachige semantische Suche nutzbar ist. Wir haben viele Ideen diskutiert, aber die Lösung war letztendlich einfach: Der Basistrainingsansatz lieferte bereits zufriedenstellende Ergebnisse. Das heißt, wir haben unsere neun monolingualen Feintuning-Datensätze zu einem großen Datensatz zusammengeführt, der aus Abfragen und Nachrichtenartikelausschnitten in neun verschiedenen Sprachen besteht. Das Training auf diesem Datensatz eliminierte den größten Teil des Language-Bias, den wir im Basismodell gemessen haben.
Warum funktioniert das? Wir sind noch dabei, das im Detail herauszufinden, aber wir können bereits ein paar Einblicke teilen:
- Es ist eine große Menge an hochqualitativen mehrsprachigen Feintuning-Daten verfügbar
- Viele Inhalte der Daten – wenn auch in unterschiedlichen Sprachen – überschneiden sich, da einige Nachrichten internationale Themen behandeln.
Wir haben unseren Ansatz „Brute-Force-Mitigation“ genannt, da eine große Menge an qualitativ hochwertigen Trainingsdaten ausreichend war, um einen Effekt zu erzeugen. Sollten Sie nicht über große Mengen an mehrsprachigen Feintuning-Daten verfügen, sondern vielleicht nur Daten in einer Sprache haben, könnte sich der Ansatz von Reimers und Gurevych [2] lohnen. Das Paper erklärt, wie man die Fähigkeiten eines bestehenden Embedding-Modells auf neue Sprachen mit einem Trainingsziel erweitert, das gleichwertige Embeddings in allen Sprachen anstrebt (d. h. „Strong Alignment“).
Referenzen:
[1] „LAReQA: Language-agnostic answer retrieval from a multilingual pool“ https://arxiv.org/abs/2004.05484
[2] „Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation“ https://arxiv.org/pdf/2004.09813
Über Cloudflight
Das könnte Sie auch interessieren
Produkt
VideoService
Verwalten und bearbeiten Sie Ihre Livestreams und Videos einfach und effizient und spielen Sie diese auf allen Endgeräten & Betriebssystemen aus.
About
APA-News
APA-News umfasst sämtliche für Redaktionen und Informationsbetriebe erforderlichen inhaltlichen und technischen Produkte und Dienstleistungen.
Produkt
MediaContact-Plus
Mit MediaContact-Plus können Sie Ihre Presseinformation individuell und professionell an Ihre Journalist:innen-Kontakte schicken.